Infratech Blog
")
Can your IT staff see the forest through the trees?
Observability. Not something that most IT departments have a line item for in their annual budget. They’ll talk about things like “monitoring” or “event management” but these are often point solutions. Ways of viewing a slice or segment of the estate, however rarely do they provide the full picture.
One of our favourite philosophers put it quite succinctly:

This situation is reflected every day in IT departments around the world. Ask your people how systems are performing, you get opinions, look at the systems in isolation and you get perspectives. Neither is giving you the truth.
So what? Why is observability so important?
Well observability matters because uptime matters. Uptime’s 2022 Outage Analysis points out three very painful facts that relate to observability:
- High outage rates haven’t changed significantly.
- The proportion of outages costing over $100,000 has soared in recent years.
- The overwhelming majority of human error-related outages involve ignored or inadequate procedures.’
Wait, so you’re going to tell me that uptime isn’t the result of good design and high-availability?
No, uptime is about good design (we are an architect group, of course we’d say that!), however its about more than good design.
That’s where observability comes in.
You see the challenge is summed up nicely by Uptime’s executive director, Andy Lawrence:
“The lack of improvement in overall outage rates is partly the result of the immensity of recent investment in digital infrastructure, and all the associated complexity that operators face as they transition to hybrid, distributed architectures,”
Funny, I recall a recent blog post by this crazy group of architects that talked about the issues around complexity….
What this is telling you is simple: As your IT systems become more complex, more interdependent, more hybrid, more distributed – legacy application monitoring and event management will not tell you what’s really happening.
In his recent article @Franklin Okeke couldn’t have said it any better:
“With more blind spots come high chances of operational inefficiencies like system downtime, poor user experience, lack of predictive insights, poor resource utilisation, etc.”
Ah, so it becomes clear. Poor observability increases both the likelihood AND duration (aka cost) of outages because of the blind-spots that it leaves in your systems.
Increased observability is critical to increasing uptime.
What is most interesting about the emerging capabilities and focus around observability when compared to traditional monitoring, is that observability is not technology focused or siloed but rather looks at the IT estate and the business as a series of joined-up capabilities.
Our 5Cubed model was created for exactly the same reason. You cannot change the network without impacting the compute, you cannot automate your control plane without having the proper tech stack below it in networks (Digital Transport) and compute (Digital Machinery). You cannot secure any of it without joining everything together with some form of Digital Intelligence.
There are definite barriers. Observability is a fairly new concept and is constantly evolving. This means it can be difficult to price, and equally difficult to forecast the real costs. Like many things in life, there’s an element of “you get what you pay for” – every tick in increased observability will see a corresponding and likely non-linear increase in the costs.
This is why we focus as much on the reduction of downtime as we do on observabilities ability to break down the silos within an IT organisation and change the conversation – making the entire IT team function as one, focused on the business outcomes rather than the technology. Observability also changes an organsation’s relationship with their service providers. Rather than a provider simple being within or out of their SLA parameters, their actual performance towards the customer’s estate and the end users can be monitored in real-time. This means that measuring and reporting on the value of both internal and external resources becomes much easier. This added insight into the IT organsiation goes a long way to establishing the value of observability to the business. Yes, observability may have a high cost, however if the combined savings it generates in reduced downtime, improved efficiency and improved supplier management are all totted up – often the observability is actually less costly than the legacy systems it replaces.
Its as simple as this:
Observability allows IT organisations to take an agile approach to the very investment in time and effort across the IT estate. It generates the data to show how each change impacts (or fails to impact) the experience of users and the cost, performance and availability of the IT services being delivered to the business.
Now let’s briefly hammer home the benefits of observability with one final argument.
Security
Have you ever seen a prison without watch towers? Why do you think that is? Why does the military spend so much of their budget on ISR (Intelligence, Surveillance & Reconnaissance). Do you or your business have CCTV?
That’s right. Observability is critical to security especially as organisations adopt DevOps, CI/CD and other forms of accelerated release cycle management. Security cannot be an afterthought. Observability needs to be built-in to DevOps (see this brilliant article from InfoWorld). Not only will it mean that developers will be able to spot and resolve issues faster, but breaches will be detected far sooner and understood far better with full-stack observability. This goes beyond our expertise (in Infratech) into a whole area of Data Observability – which is also well worth investing in for organisations at that level of maturity.
For now (yup, sales pitch incoming!), consider that your teams likely cannot see the forest through the trees. Their inward, operational focus means that they’re ill positioned to understand where observability can add value, what value it will add, and how to best realise that value. That outside-looking-in perspective is why you hire an architect!


Addressing the skills shortage in infrastructure and “hard computer science”
When one of our founders went back to his secondary school in 1999 for a visit to thank the people of the computer science department who had supported him racing ahead in his career, he discovered that the computer science department had been closed! This was peak “dot-com”, however the school said that due to low enrolment they had shut down the program, replacing it with a spattering of “digital skills” courses in using computing technology to do things (coding, graphic design, business apps…). Gone was the course that taught you how to design and build the computer system – it was simply assumed that “it already exists”.
What this looks like has been explored in some detail (from the US perspective, though the same trends would apply to any of the western nations) by the ITIF (‘Information Technology & Innovation Foundation’).
This graph from that study tells the story better than any words could:
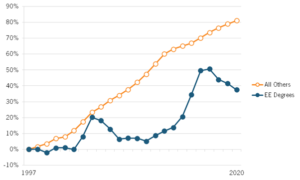
Yes, you read that graph correctly.
Since the Dotcom boom degrees awarded in Electrical, electronics and communications engineering have grown far slower than all others, and this growth in the early 21st century has actually been slowing!
Looking out further the stats are even more frightening. At the IEEE VLSI Symposium in 2022 (The IEEE is the parent organization responsible for layer 1 & 2 on the OSI model and much of our modern telecommunications technology) they identified a 90% drop in EE enrolment in the USA vs computer science (the science of applying computer technology i.e. programming and software development).
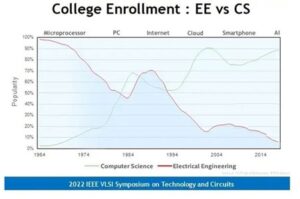
The skills needed to design and build the computer systems we rely on are just not being developed anymore. Increasing numbers of people are entering the workplace with the assumption the computer systems already exist and work.
Forbes has confirmed that the issue is already being felt here in the UK. 93% of UK businesses have identified an IT skills gap.
No where is this skills gap worse than in areas of infrastructure design and engineering. These lower 5 layers of the OSI model start with the physical (cables, power, equipment) and extend up to the networks, datacentres and clouds that the exiting and emerging technologies like AI and machine learning all depend on.
You aren’t going to have any AI without a hardware and a network somewhere to run it.
In the Forbes study 41% of respondents said “insufficient training opportunities” and 37% a “lack of relevant education programmes” were to blame for the skills shortage. What this fails to explain is that as infrastructure becomes more complex, more virtual, and generally more powerful there are fewer and fewer opportunities for people to develop and maintain these skills in the workplace. Companies do not have buildings full of computer and telecoms hardware anymore, they rent it “as-a-Service” from a mix of different providers.
This means that while the students are more interested in “soft computer science” there is also less opportunity to learn and get hands-on with “hard computer science”. Infrastructure however, is fundamentally hard. Behind that cloud, that web software, or that unified comms… somewhere… deep in… (Slough usually!) there’s still a building full to the rafters with computer and telecoms hardware, power, cooling, networks and cabling.
At Infratech Digital, we have had to create our own unique training program to grow and develop the infrastructure architects of the future ourselves.
This is why we firmly believe, at least where Infratech is concerned, that IT consumers should not even try to hire internally. There is just no way that an IT consuming organisation can compete with the hyper-scalers and service providers for the learning and development opportunities they offer. Without this, and with the state of education in these core electronics and telecommunications technology lacking, any infrastructure staff going to work for an airline, a bank or the public sector will, frankly, just not be very good. If they were good they would already be working for a service provider making a lot more money than a consuming organisation could afford.
Bottom line, most organisations should face up to the fact that the skills shortage is not going to get better, it will continue to get worse. The solution therefore is to stop looking for those skills as internal hires and strengthen your IT teams user-experience facing skills (coding / BI / app development), supplier ecosystem, and consider implementing internal SIAM (Service Integration and Management)… but that’s for another blog.
For now, any time you need Infratech experience, start with a team of brilliant and experienced Infratech architects who have developed their own training to solve the skills-gap and fostered people who live and breath the lower OSI layers every day, for organisations of all types. They will then help you engage successfully with the right service providers, on the right terms to deliver real results for your business… something about “outcome obsessed” comes to mind.
Dealing with technical debt and the kludge
McKinsey refers to technical debt as a “tax a company pays on any development” and according to their research it accounts for as much as 40 percent of most organisations IT balance sheets.
How did we get here?
To understand technical debt its important to understand an often borrowed German word the “kludge”. The Oxford defines kludge as “an ill-assorted collection of parts assembled to fulfil a particular purpose”. Why is this word so important to understanding technical debt? Because in IT, engineers are particularly likely to have created more than a few “kludges” to meet a demand (fulfil a particular purpose) when under pressure from business and management to deliver faster and/or cheaper solutions.
This is a particular issue in IT because unlike other areas of engineering, there is a perception that kludging something together has no downside. If it was physical infrastructure such as a building or a road there would be a physical safety concern and a kludge would never be tolerated. Because we do not see IT that way (even when today it might be a physical danger), its acceptable to “just make it work”.
This starts off a vicious cycle where pressure to keep up means complex solutions (aka kluges), leading to installed complexity which only adds to the pressure to keep up.
What is important to understand is that the vendor narrative that technical debt is due to “old technology” is not the whole truth. Vendors want you to believe that simply keeping all your technology “current” that it will be easier to manage. Certainly old technology can eat up time from your IT team maintaining and patching it. However, consider the reality in the service provider world, where never have they rolled a van to replace something in the network, in a street cabinet, simply because it was “old”.
KPMG’s 2022 study into technical debt said: “ About three-quarters of respondents (73%) to the survey said the long-term maintenance costs attached to deploying systems have little to no impact on their IT ambitions.”
That paints a very different picture from the one the vendors are promoting. The reality is somewhere in between. Long-term maintenance costs are a serious concern, and customers should be factoring it in when making IT decisions. However age is not a reason to replace something that is perfectly functional.
So where does technical debt come from?
One word.
COMPLEXITY
Remember what we said about those kluges? That is where the real issue comes from and what is actually creating technical debt. By taking shortcuts or generally doing things without proper architectural design means that IT systems become increasingly complex over time. An old system that is simple, sits there, does its job… it might require a bit of patching, or ring-fencing to protect it from more evolved threat actors, but if its simple it will be easy and cost-efficient to maintain, why replace it! It works! On the other hand a brand new system which is implemented with haste, high complexity and without proper design or forethought into long-term maintenance will rapidly become a millstone around the neck of your IT teams.
KPMG summed it up as such: “To avoid creating fragmentations that could harm customer interactions, blueprints for emerging technologies should not overlook the importance of minimising tech-debt responsibilities,”
“Fragmentations”…. Kluges by another name. Complexity.
What is the solution?
Sorry, sales pitch incoming… that’s right. Sound architectural design.
Simple and elegant is unfortunately not automatic. Technology is increasingly complex. Virtual, software-defined, DevOps, all brilliant advancements that have only made design more flexible. This added flexibility is great, for an Architect. It’s the same as the move from building with stones to concrete. The fluid nature of modern man-made materials has meant that architects can design wild and imaginative buildings… or absolute monstrosities. Because design is not automatically elegant, it takes work and concreted effort.
By working with an Architect, someone who is not mired with the “this is how we’ve always done it” and can bring a fresh perspective. By working together with your internal teams and suppliers, key issues around long-term maintenance and complexity can be explored and properly understood. Roadmaps will be created and implemented that will guide future IT initiatives.
Over time complexity will come down, and with it, technical debt. Guidelines can be put in place to make this managing down process part of the organisation’s “evergreen” strategy so that no more than 20% of any project budget is spent towards managing technical debt.
By utilizing the Infratech Method and our 5States, organisations will be able to form a much clearer picture of their estate and its current life-cycle stage. This insight is invaluable in determining which technical debt to manage, and which to eliminate, and more importantly when these activities should take place within the wider IT workplan.
1st Dec 2023
What is Infrastructure eXperience?
Businesses today talk a lot about CX or “Customer eXperience”… usually measured in Net Promotor Scores. A few years before that all the App and technology designers were obsessed with UX “User eXperience”. Before even that the phone companies used what they called “Mean Opinion Scores” to decide if a phone call was good enough to keep customers happy and paying the (usually rather large!) per minute charges.
Through all of this, Infrastructure eXperience or ‘IX’ has been there, we just weren’t talking about it.
Think back to your own personal experiences with modern infrastructure…
Have you ever seen the city redesign a road or intersection only for it to be so bad to drive on that they had to immediately put it back to its original design, or change it even further?
Have you ever had 5 bars of signal on your mobile phone but still couldn’t get a webpage to open?
Have you ever moved to a new PC or cloud service and had it run slower or take longer to get the work done than the one it replaced?
If any of these are familiar, you’ve experienced poor IX!
Infrastructure eXperience is defined as a score, from 1-5, of how well the supporting Infratech (that’s Infrastructure Technology for those new to us) is able to deliver the required service to the user.
That road network? Its goal isn’t to look pretty, it’s to move traffic. The signal on your mobile? Its only useful if you can browse the web and access data services. The new PC or Cloud service? Total waste of money if it doesn’t make your work faster.
Of course IX is a tricky thing to measure. Is a new network better because it has higher theoretical speeds? No. Not unless the average speeds to the user also improve.
This has been the challenge with Infratech for many years now. Everyone has been so caught up by Moore’s Law and the ever increasing theoretical capability of our technology that we often don’t stop to question whether the experience its delivering is actually any better. Bill Gates once said “no one will ever need more than 64KB of RAM” – well as I’m writing this to you my PC is using 14.7GB of RAM to run the operating system, a few chat windows and a word processor! How much of that added memory requirement has improved my experience?
Technology should never be replaced because its old.
Instead, organisations need to learn to understand and cultivate focus on steady improvement of their Infrastructure eXperience. This will guide them to determine what technology to replace, when and with what. Often poor decisions in the past have left organisations with mountains of technical debt – technology which not only doesn’t benefit IX, but actively detracts from it! This is because the tech industry has been interested in only one thing – selling you new technology! They don’t spend the time it takes to understand how to effectively retire the existing technology, so bits get left hanging around. The net result, lots of spend on new technology with a steadily decreasing IX and mounting technical debt.
Most of us can relate to the fact that our personal experience with technology is often more advanced and in many ways superior to our work experience. That’s because the typical service provider for consumer tech ruthlessly retires technology. That phone from 5 years ago? Not supported, buy a new one. Of course this isn’t ideal either, infrastructure is big, costly, complex. Imagine if we “threw out and replaced” all the roads and rail every 4-5 years? That’s what the tech vendors would have us do if they were in charge!
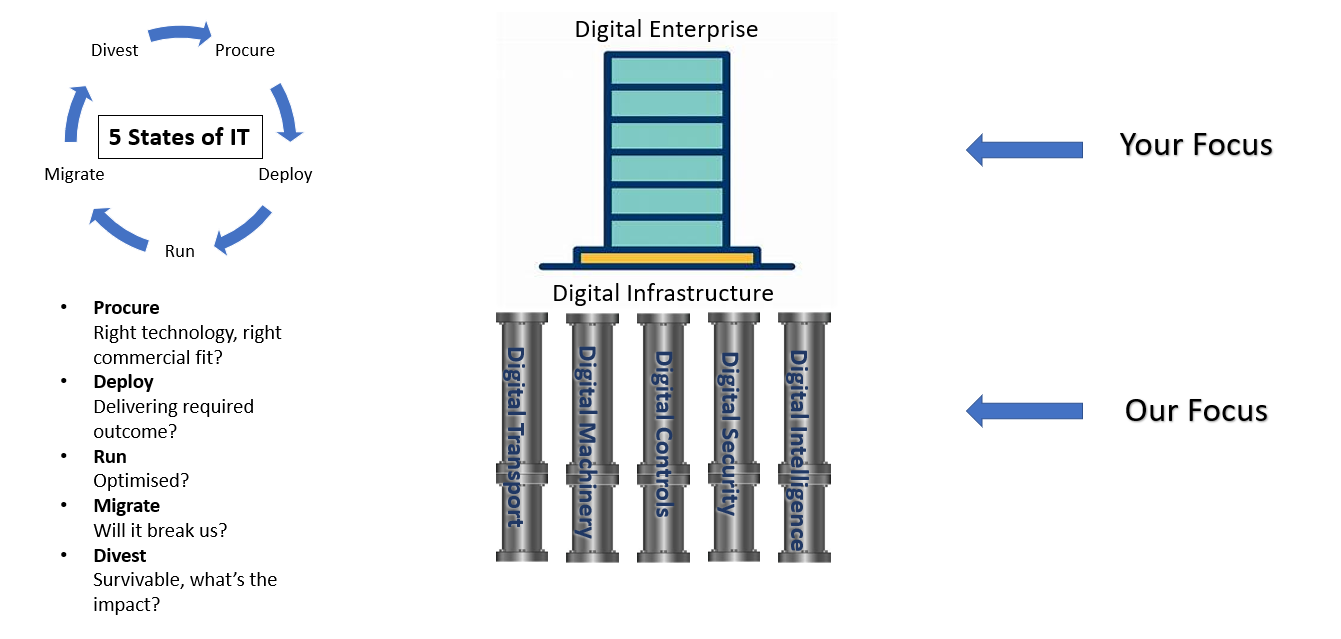
The Infratech 5Cubed Method and its 5States concept help resolve this challenge. By understanding, for each piece of technology, where it is in its lifecycle:
- Procurement
- Deployment
- Operation
- Migration
- Divestment
One can now understand the impact of that technology on the overall IX of the organisation. Understanding is the first step towards having a positive impact.
Armed with the knowledge of that impact, its then possible to create a backlog of work that’s needed to move the technology forward to its next state. Once we have that roadmap, we can create detailed “sprint plans” for the work. We can also understand what the impact should be, and therefore assure (measure) it after the work is complete. Finally we can iterate across the organisation doing the same with all of the interconnected technologies. In this way IX is constantly improved, and spend on “refresh” is minimised.
If your mission is to deliver better CX, we think you need to take a hard look at your IX first.
IX makes everything you are trying to do as a digital enterprise possible.
Don’t be one of the statistics, the 70% of organisations who fail digital transformation, because no-one laid the foundations for success.
The five pillars of Infratech are what deliver solid, predictable IX outcomes.

7-Jul
What’s the meaning behind the Infratech logo?
To answer that question you have to remember a time when someone said “solving this problem is a bit like peeling an onion”. We do that a lot at Infratech Digital – peeling Infratech-shaped onions for our customers and partners.
Whether it’s the layers of the OSI model, the layers of a defence-in-depth design, the layers of an Identity Management and Governance model or the layers of an architectural Enterprise Continuum – there are always layers.
The thing with Infratech is that customers and service providers alike always look at their digital infrastructure from the outside looking in. They don’t see the layers, only the shell. It takes an IX expert to peel them back and expose the breaks in each layer – and explain how those breaks are combining to create real weakness – be that in operational efficiency, security, scalability or reliability.
Ever seen how rammed earth footings are made for a building? Layers.
How do you visualize a multi-mode transportation system? Layers.
What’s the secret to samurai swords incredible strength and performance? Layers.
So our logo? It’s a layers thing.
Day 0 has arrived
24-June-2023
It’s official! Infratech Digital (UK) Limited is registered with company’s house as our vehicle for changing the world of IT.
Why did we do all this? Is it just because we like self-inflicted suffering?
No not really. Andrew and I are really just fed-up with a lifetime of watching really important IT infrastructure projects go absolutely pear-shaped and end up costing a fortune and delivering very little.
In the earlier years in IT, it didn’t matter as much if projects ran a bit late, or a bit over budget because the techies were playing with their new toys… IT was an afterthought, something you did as an extra – but not something that meant the life (or death) of your business.
Today IT is everything! Without it, most businesses don’t have a business! Why then is it treated with such disregard for professionalism, quality and value by so many? Its not a toy-set anymore!
We both realized that the industry needs change. Customers can no-longer approach the technology directly – its too complex. The technology providers are so deep into the tech that they can’t understand the lack of knowledge among customers – and frequently this knowledge gap kills projects.
Much like law, medicine, accounting, and indeed architecture – a profession eventually grows up. We are those grown-ups.
IT is not a toy, it’s the foundation of the digital enterprise. We’ll be the architects, and we’ll keep all the providers in line each doing their part to a high-standard so that collectively we all reach a good outcome. Profit made, value delivered, dials moved – outcome achieved!


Our Concept Was Conceived
2-May-2023
Andrew and I found ourselves in the Queens Hotel in Leeds trying to figure out how to explain our combined excess of 50 years of professional technology infrastructure to an audience who scarcely knows it exists!
To quote A.C. Clarke “any sufficiently advanced technology is indistinguishable from magic”
Ask anyone today where their data is stored and they’re likely to say something like “in the cloud” without any realization that this cloud they speak of is just someone else’s hardware in a datacentre they’ve not seen or visited.
There is no magic – only Infratech!
By the end of a furious few hours of white-boarding the 5cubed approach was born!
Aspect 1: What is Infratech? = The Five Pillars
- How do we define it all for the layman, and relate it to something people can understand
Aspect 2: What are the work outputs? – The Five Artefacts
- Now what – specifically what architectural work needs to get done on these pillars to ensure success and valuable outcome?
Aspect 3: Why & When = The Five States of IT!
- What are the triggers and key inflection points where requirements and activities need to change significantly.
With that, we stake out new ground in the IT industry, bringing the Design + Build concept to digital infrastructure and introducing a totally new concept in how you view and plan core IT – the Infratech method.
Who We Are
Our Founders
Core Principles
WinCubed
Methodology
5cubed
5pillars
5states
Outcomes
IX Assessment
IX Skills
IX Sprints
Contact Us
Blog
This website features materials protected by the Fair Use guidelines in international law. All logos, brands, other copyrighted materials and trademarked property remain the exclusive property of their respective owners. All rights reserved to their respective owners. Infratech Digital is using these marks under fair use, and without express permission on the basis of the past trading relationships of the founders and their previous companies. Any request for the removal of a logo may be sent to [email protected]